Abstract
Egocentric videos provide valuable insights into human interactions with the physical world, which has sparked growing interest in the computer vision and robotics communities. A critical challenge in fully understanding the geometry and dynamics of egocentric videos is dense scene reconstruction. However, the lack of high-quality labeled datasets in this field has hindered the effectiveness of current supervised learning methods. In this work, we aim to address this issue by exploring an self-supervised dynamic scene reconstruction approach. We introduce EgoMono4D, a novel model that unifies the estimation of multiple variables necessary for Egocentric Monocular 4D reconstruction, including camera intrinsic, camera poses, and video depth, all within a fast feed-forward framework. Starting from pretrained single-frame depth and intrinsic estimation model, we extend it with camera poses estimation and align multi-frame results on large-scale unlabeled egocentric videos. We evaluate EgoMono4D in both in-domain and zero-shot generalization settings, achieving superior performance in dense pointclouds sequence reconstruction compared to all baselines. EgoMono4D represents the first attempt to apply self-supervised learning for pointclouds sequence reconstruction to the label-scarce egocentric field, enabling fast, dense, and generalizable reconstruction. The interactable visualization, code and trained models have been released.
Reconstruction Results
Check out more details in the interactive results below for 4D Egocentric Scene Reconstruction.
Interactive ResultsMethod Overview
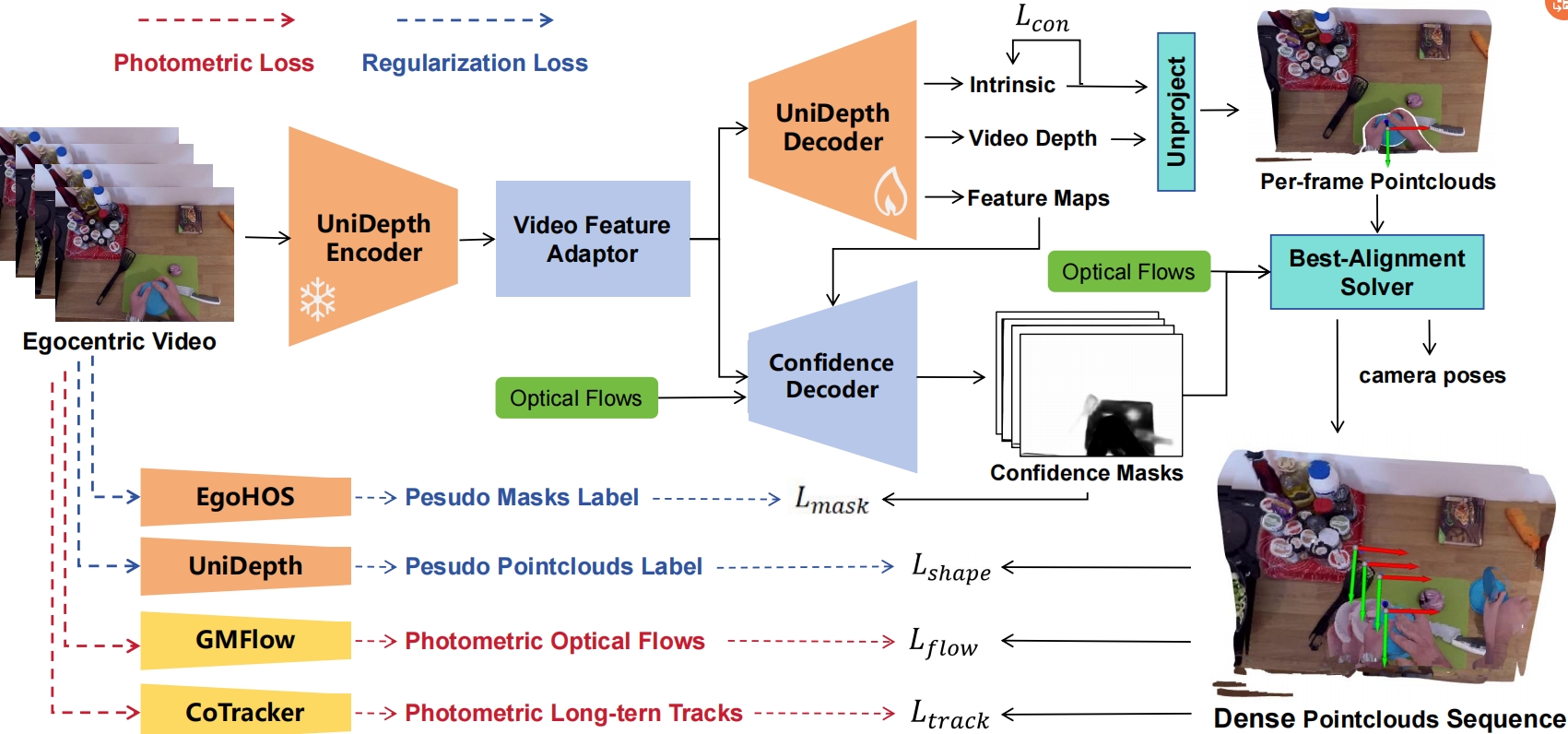
The overview of EgoMono4D and our self-supervised training framework. The model first simultaneously predicts camera intrinsic, video depth, and confidence maps (for camera pose estimation). Camera poses are then calculated by aligning unprojected pointclouds from different frames with confidence maps. The final dense pointclouds sequence reconstruction is assembled using all the predicted variables. We train our model purely on unlabeled egocentric video datasets, with both self-supervised photometric loss for depth alignment and regularization loss for training stablization. Please check out the paper for more details.
Quantative Results
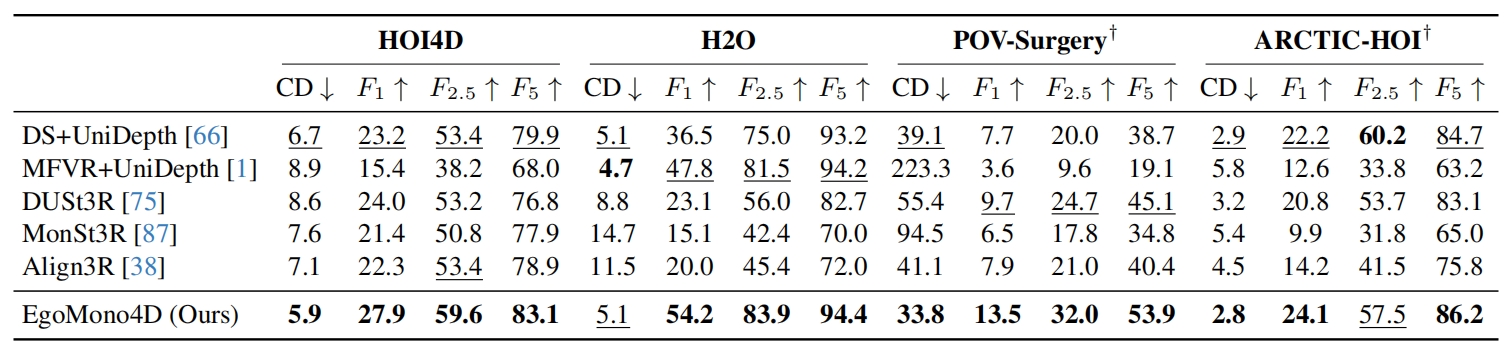
We evaluate EgoMono4D and baseline models on 4 egocentric datasets. The evaluation results for 4D pointclouds sequence reconstruction are presented, using 3D Chamfer Distance (mm) and 3D Pointclouds F-score (%). For ARCTIC-HOI, the evaluation focuses specifically on the reconstruction quality of the hand-object region. On average, EgoMono4D demonstrates a clear advantage across the metrics. It is important to note that this does not imply that supervised methods are inherently inferior to self-supervised ones. In domains with abundant labeled data, supervised methods may offer advantages, as demonstrated in depth estimation tasks. However, in the context of ground-truth label scarcity, self-supervised methods like EgoMono4D can provide a viable alternative.
BibTeX
@article{yuan2024self-supervised,
title={Self-Supervised Monocular 4D Scene Reconstruction for Egocentric Videos},
author={Yuan, Chengbo and Chen, Geng and Yi, Li and Gao, Yang},
journal={arXiv preprint arXiv:2411.09145},
year={2024}
}